Maximising the Potential of AWS High-Performance Computing Services

AWS Certified Security Specialist, highly motivated result-oriented DevSecOps and Cloud Solution Architect with comprehensive hands-on experience in Digital Transformation, DevOps, CI/CD, designing and implementing highly scalable architectures and infrastructure for end-to-end solutions. A positive and multi-skilled character with a proven ability to successfully deliver high-quality solutions with the good use of personal initiatives, very often in complex and challenging customer environments.
AWS HPC Services Overview
AWS provides a robust suite of High-Performance Computing (HPC) services, empowering organisations to execute large-scale simulations and deep learning workloads in the cloud. AWS HPC services offer virtually limitless compute capacity, a high-performance file system, and high-throughput networking, enabling faster insights and reduced time-to-market.
Key AWS HPC services include:
Amazon Elastic Compute Cloud (EC2): Provides secure, resizable compute capacity to support a wide range of workloads.
Elastic Fabric Adapter (EFA): Facilitates scaling of HPC applications across numerous CPUs and GPUs, offering low-latency, low-jitter channels for inter-instance communications.
AWS ParallelCluster: An open-source tool that simplifies the deployment and management of HPC clusters.
AWS Batch: A cloud-native batch scheduler that scales hundreds of thousands of computing jobs across all AWS compute services and features.
Amazon FSx for Lustre: A high-performance file system that processes massive datasets on-demand and at scale with sub-millisecond latencies.
These services, combined with AWS's fast networking capabilities, allow organisations to accelerate innovation, maximise operational efficiency, and optimise performance.
Essential Best Practices for HPC on AWS
When designing, deploying, and optimising HPC workloads on AWS, consider the following best practices:
Architectural Design: Choose the right combination of AWS services based on your workload characteristics. For compute-intensive workloads, Amazon EC2 is an excellent choice, while AWS Batch is ideal for batch processing jobs.
Workload Distribution: Distribute workloads across multiple AWS services to maximise resource utilisation and performance. AWS ParallelCluster is excellent for managing HPC clusters, and AWS Batch is ideal for job distribution.
Performance Optimisation: Select the right instance types, use Elastic Fabric Adapter for low-latency communications, and leverage Amazon FSx for Lustre for high-performance file systems.
Cost Optimisation: Use Spot Instances for non-time sensitive workloads to save costs. Spot Instances can be integrated into AWS Batch and AWS ParallelCluster to run HPC workloads at a fraction of the cost. Also, consider using Savings Plans or Reserved Instances for predictable and consistent workloads.
Security and Compliance: Implement strong access controls using AWS Identity and Access Management (IAM), protect data at rest and in transit using encryption, and ensure compliance with industry standards and regulations.
Scalability: Design your HPC workloads to be scalable. Use services like AWS Auto Scaling to automatically adjust capacity to maintain steady, predictable performance at the lowest possible cost.
Resilience: Implement fault tolerance and high availability in your HPC architecture. Use multiple Availability Zones to ensure your application remains available even if one data centre fails.
Monitoring and Logging: Use AWS CloudWatch to collect and track metrics, collect and monitor log files, and set alarms. AWS CloudTrail provides event history of your AWS account activity for governance, compliance, operational auditing, and risk auditing of your AWS account. For HPC workloads, monitor metrics such as CPU and GPU utilisation, network throughput, and storage I/O operations.
Automation: Automate your infrastructure as much as possible. Use AWS CloudFormation or Terraform for infrastructure as code, and automate your deployments using AWS CodePipeline and AWS CodeDeploy.
Data Management: Use appropriate storage solutions for your data. Amazon S3 is great for object storage, Amazon EBS for block storage, and Amazon FSx for Lustre for high-performance file systems. For HPC workloads, consider using Amazon FSx for Lustre, which is designed for applications that require fast storage – where speed matters, fast processing is required, and non-sequential read/write access is common.
Each of these best practices can help you maximise the benefits of AWS HPC services, ensuring you get the most out of your investment.
AWS HPC Scenarios and Reference Architectures
AWS HPC solutions can be deployed in various scenarios, each with its unique architecture. Here are some of the key scenarios:
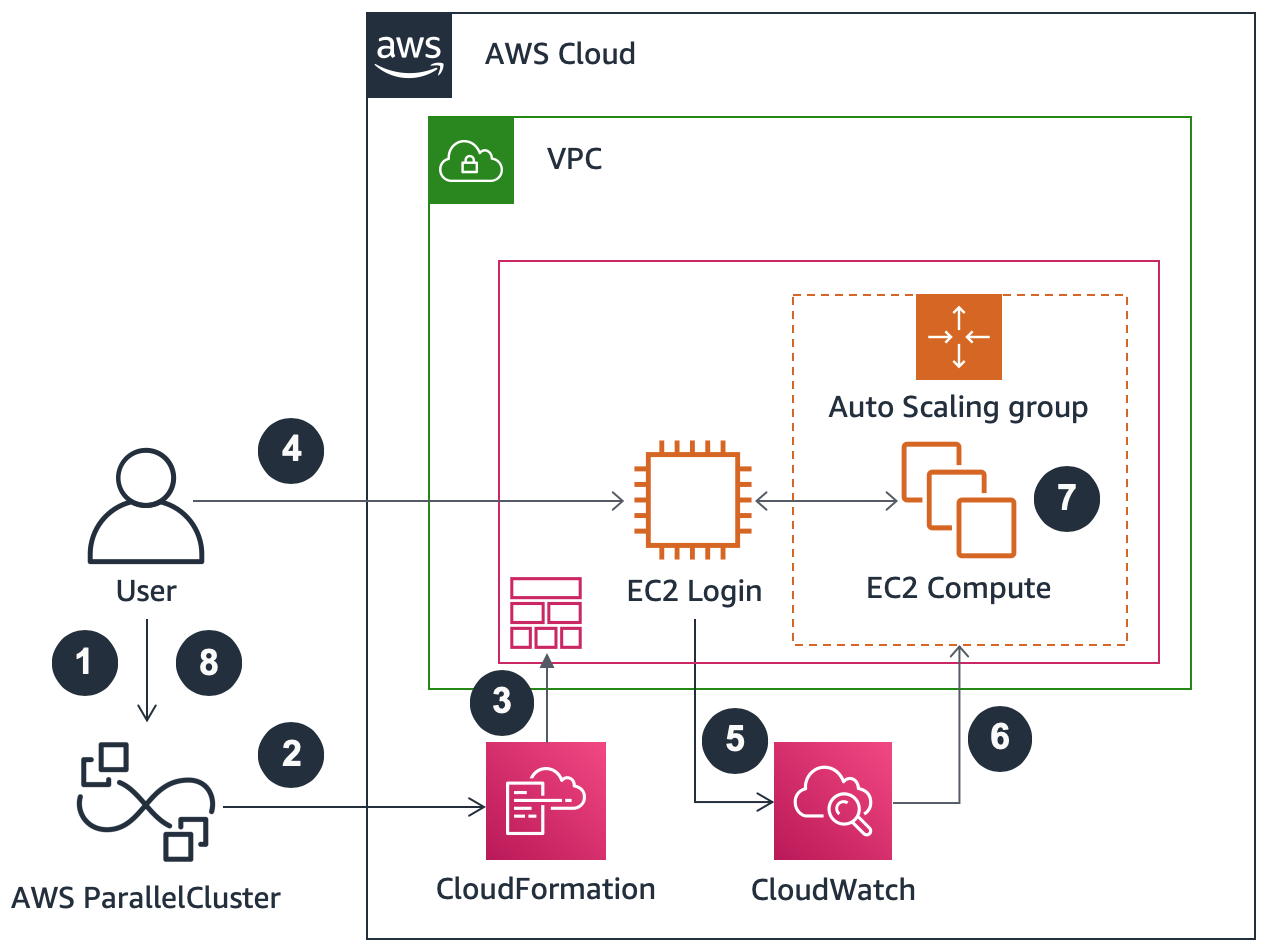
1- Traditional Cluster Environment
Many users begin their cloud journey with an environment similar to traditional HPC environments, often involving a login node with a scheduler to launch jobs. AWS ParallelCluster is an example of an end-to-end cluster provisioning capability based on AWS CloudFormation. It provides an HPC environment with the “look and feel” of conventional HPC clusters, but with the added benefit of scalability. Traditional cluster architectures can be used for both loosely and tightly coupled workloads. For best performance, tightly coupled workloads must use a compute fleet in a clustered placement group with homogeneous instance types.
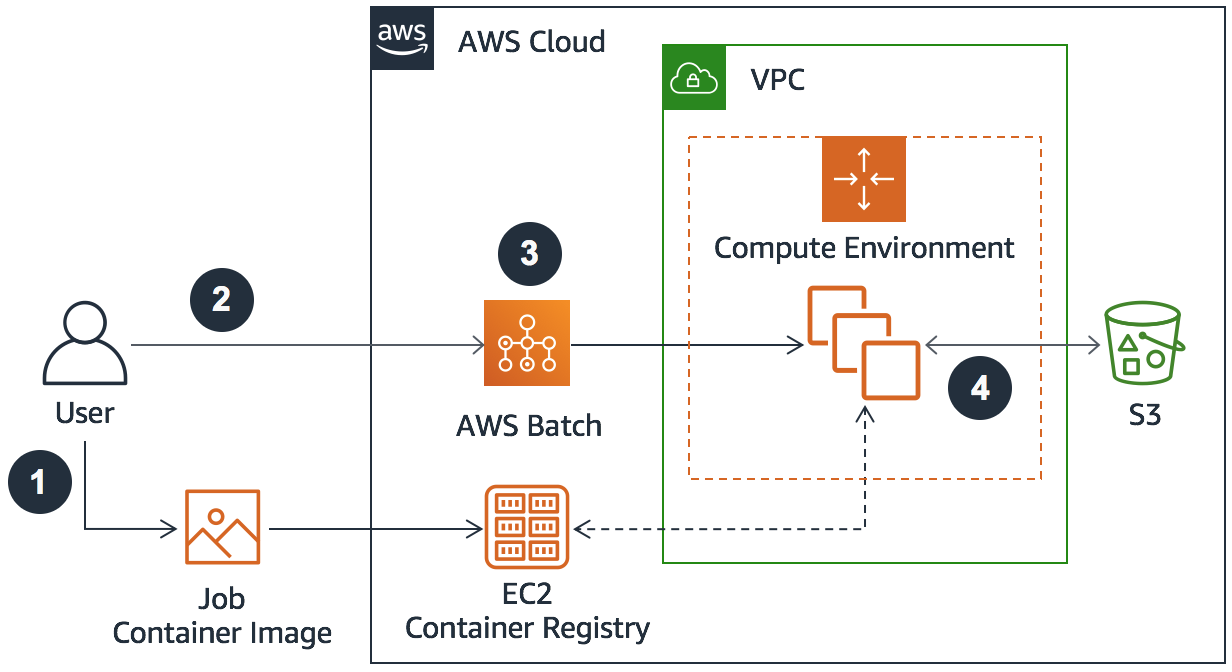
2- Batch-Based Architecture
AWS Batch is a fully managed service that enables you to run large-scale compute workloads in the cloud without provisioning resources or managing schedulers. It dynamically provisions the optimal quantity and type of compute resources based on the volume and specified resource requirements of the batch jobs submitted. An AWS Batch-based architecture can be used for both loosely and tightly coupled workloads. Tightly coupled workloads should use Multi-node Parallel Jobs in AWS Batch.
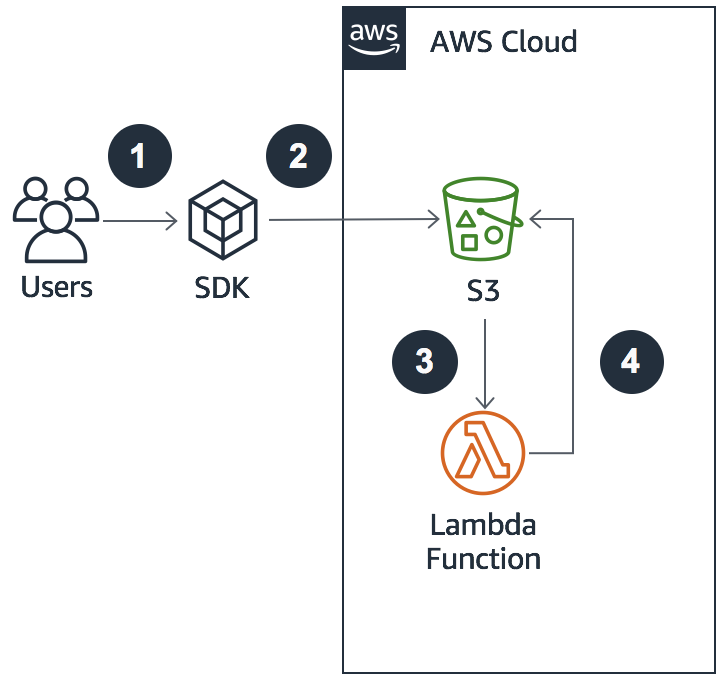
3- Queue-Based Architecture
Amazon SQS is a fully managed message queuing service that makes it easy to decouple pre-processing steps from compute steps and post-processing steps. A queue-based architecture with Amazon SQS and Amazon EC2 requires self-managed compute infrastructure, in contrast with a service-managed deployment, such as AWS Batch. A queue-based architecture is best for loosely coupled workloads and can quickly become complex if applied to tightly coupled workloads.

4- Hybrid Deployment
Hybrid deployments are primarily considered by organizations that are invested in their on-premises infrastructure and also want to use AWS. This approach allows organizations to augment on-premises resources and creates an alternative path to AWS rather than an immediate full migration. Depending on the data management approach, AWS provides several services to aid in a hybrid deployment. For example, AWS Direct Connect establishes a dedicated network connection between an on-premises environment and AWS, and AWS DataSync automatically moves data from on-premises storage to Amazon S3 or Amazon Elastic File System.

5- Serverless Architecture
The loosely coupled cloud journey often leads to an environment that is entirely serverless, meaning that you can concentrate on your applications and leave the server provisioning responsibility to managed services. AWS Lambda can run code without the need to provision or manage servers. In addition to compute, there are other serverless architectures that aid HPC workflows. AWS Step Functions let you coordinate multiple steps in a pipeline by stitching together different AWS services. Serverless architectures are best for loosely coupled workloads, or as workflow coordination if combined with another HPC architecture.
In the next section, we will discuss the crucial security considerations specific to HPC workloads on AWS.
HPC Security Considerations
Security is paramount when dealing with HPC workloads especially with sensitive data on AWS. Key considerations include data protection, access control, network security, and compliance with industry standards and regulations. AWS provides numerous security features and services, such as AWS Identity and Access Management (IAM) for access control, AWS Key Management Service (KMS) for data encryption, and AWS Security Hub for comprehensive security and compliance management.
Common Pitfalls and Challenges
Adopting AWS HPC services can come with its own set of challenges. Some common pitfalls include:
Inadequate Planning: Without proper planning and understanding of the workloads, you may select inappropriate services or resources, leading to increased costs or poor performance.
Lack of Security Measures: Neglecting to implement robust security measures can lead to data breaches or compliance issues.
Inefficient Resource Utilisation: Not optimising for cost and performance can result in wasted resources and increased expenses.
Lack of Monitoring and Logging: Without proper monitoring and logging, it can be difficult to troubleshoot issues or understand the performance of your HPC workloads.
To overcome these challenges, it's crucial to plan your HPC workloads carefully, implement robust security measures, optimise resource utilisation, and set up comprehensive monitoring and logging implemented according to AWS Well-Architected-Framework's HPC High Performance Computing Lens.
AWS Batch or AWS ParallelCluster?
Selecting the appropriate AWS HPC service for your workloads hinges on your specific requirements. Here's a concise comparison to guide your decision:
AWS ParallelCluster is an AWS-supported open-source cluster management tool that makes it easy to deploy and manage HPC clusters in the AWS cloud. It's designed for workloads that need specific, complex cluster setups and supports multiple instance types, job queues, and schedulers, including AWS Batch and Slurm. With automatic resource scaling, simplified cluster management, and seamless cloud migration, AWS ParallelCluster is an excellent choice for managing intricate HPC workloads.
AWS Batch, on the other hand, is a fully managed batch processing service. It's designed for workloads that require substantial batch processing and can leverage the automatic scaling capabilities of AWS. AWS Batch dynamically provisions the optimal quantity and type of compute resources based on the volume and specific resource requirements of the jobs submitted.
In essence, AWS ParallelCluster offers more control and is suited for complex HPC workloads, while AWS Batch is ideal for large-scale, compute-intensive batch jobs. Your choice should align with the nature of your HPC workloads and the level of control and scalability you require.
AWS HPC Use-Cases and Success Stories
AWS HPC services have been instrumental in propelling numerous enterprises, start-ups, and SMBs towards accelerated innovation and a competitive edge. For instance, AstraZeneca, a multinational pharmaceutical and biopharmaceutical company, leveraged AWS Batch to optimise its genome analysis pipeline. This not only streamlined their operations but also led to significant breakthroughs in their research.
Conclusion
AWS High-Performance Computing services offer a powerful suite of tools that can significantly accelerate innovation, reduce time-to-market, and tackle complex problems. By following best practices, leveraging the AWS Well-Architected Framework, and understanding the key considerations and potential pitfalls, organisations can effectively harness the power of AWS HPC services to drive their business forward.
Moreover, if you're interested in optimizing your cloud journey and digital transformation strategies, please consider subscribing to "ioTips" as well. Each edition of "ioTips" delivers industry best practices and tips focusing on security, performance, cost optimization, and operational excellence.



